大会管理系统
一站式数字会议管理全案

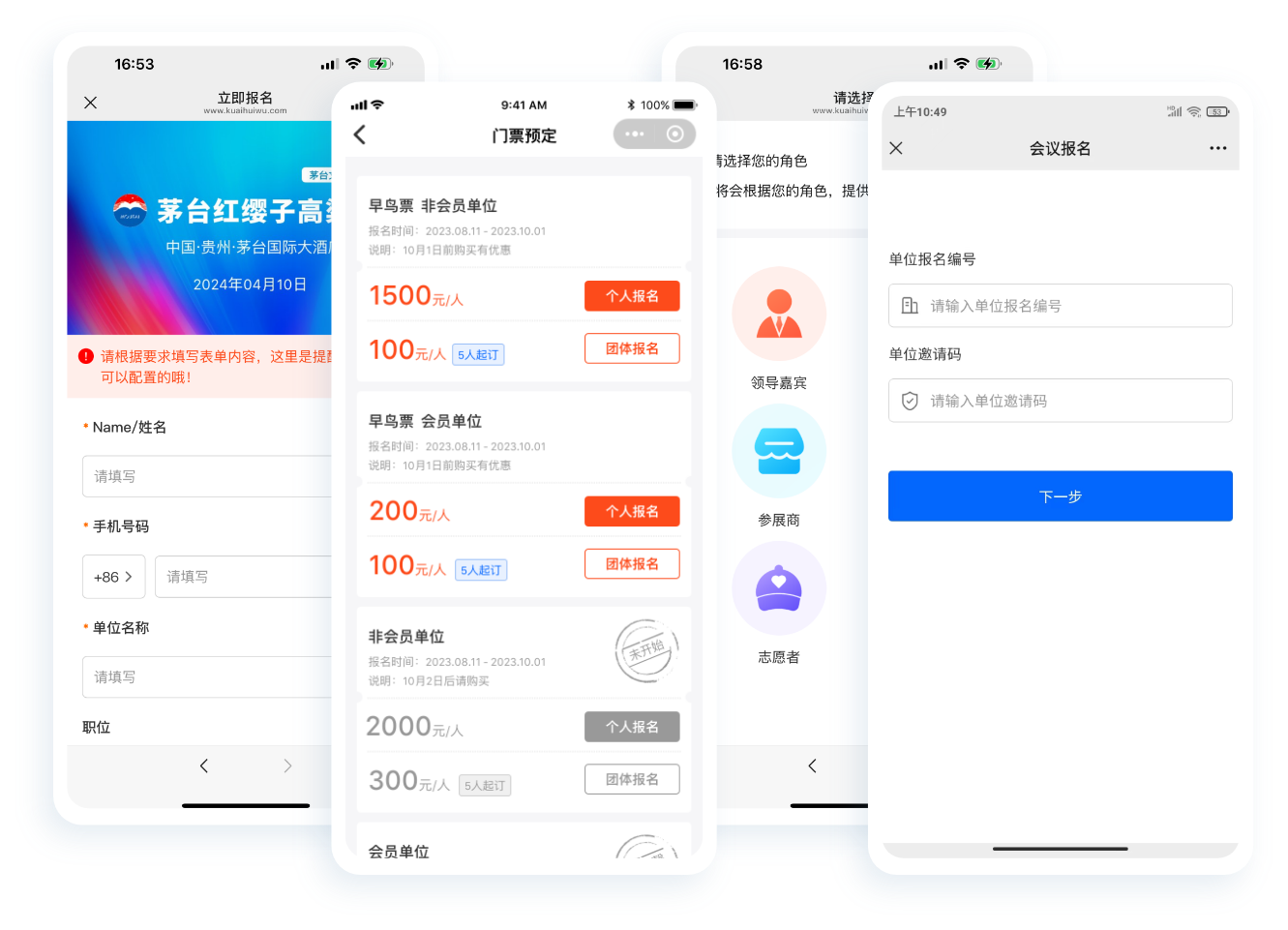
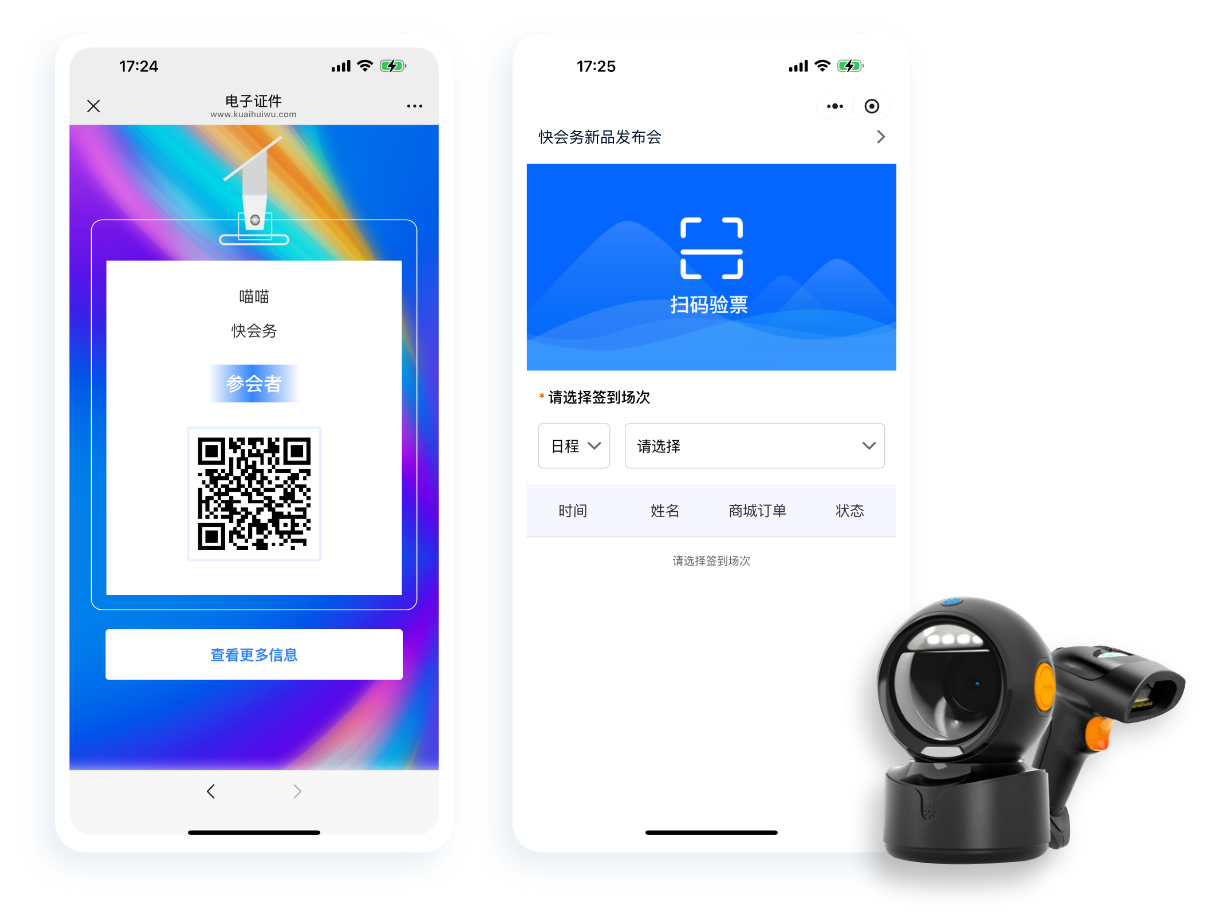
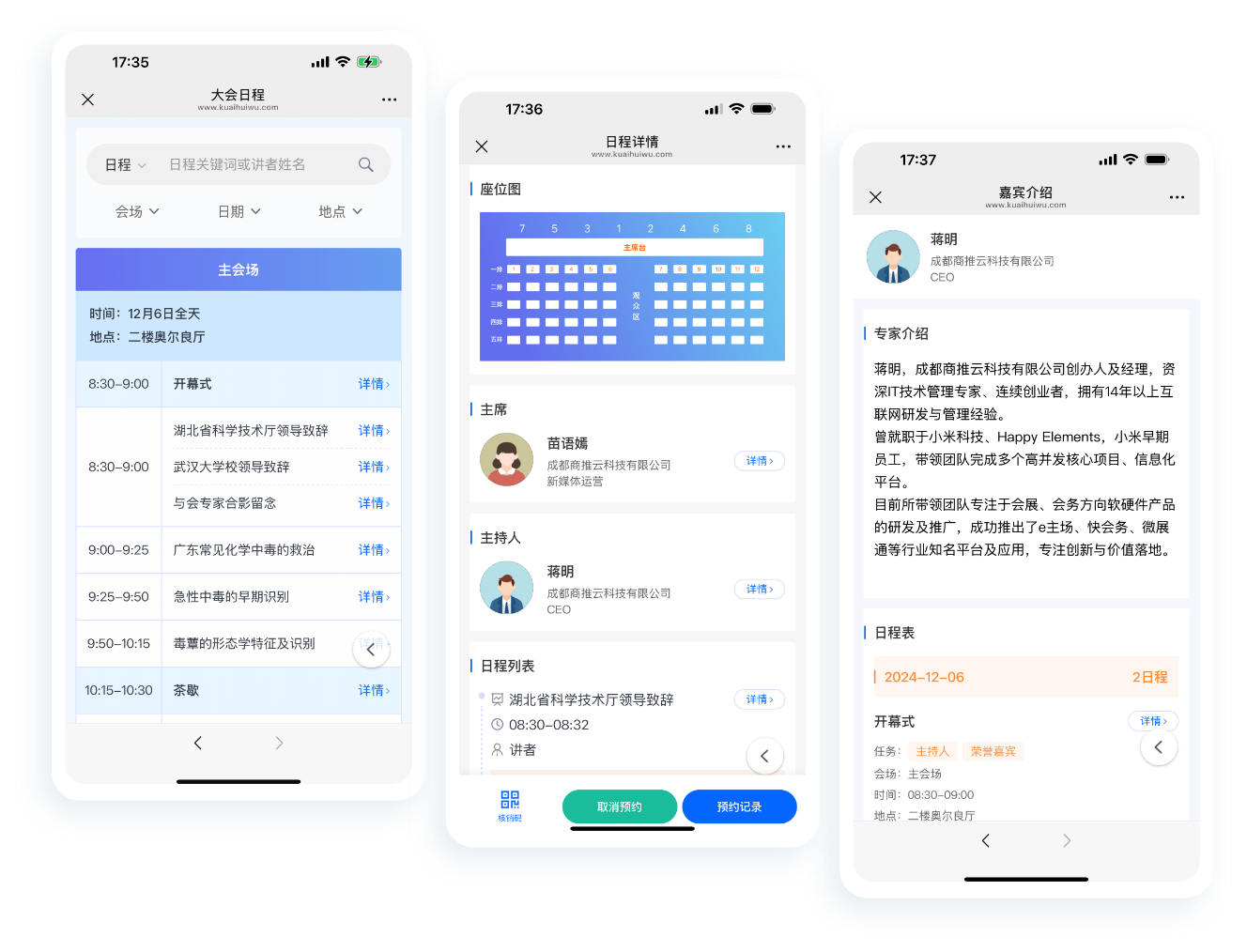
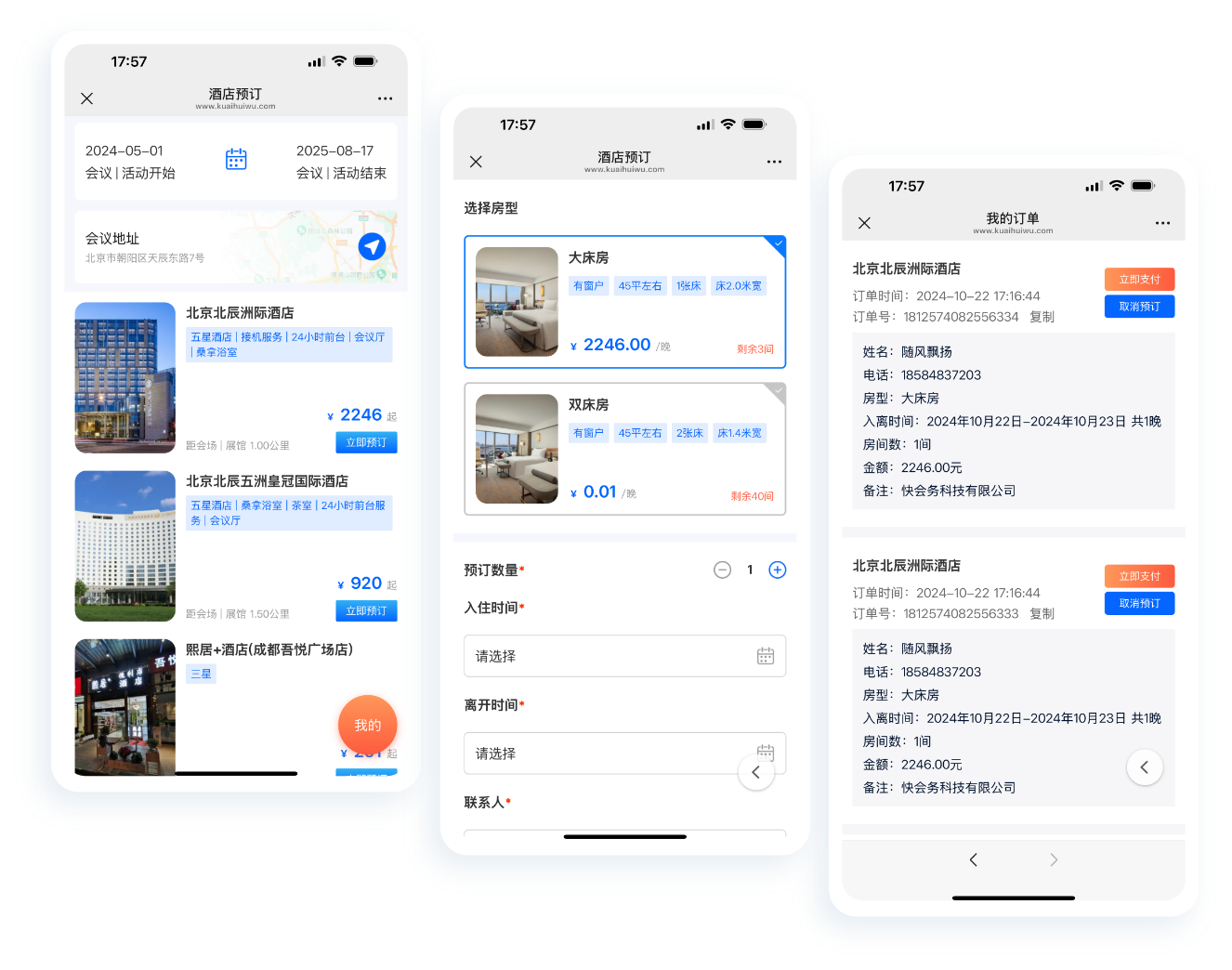
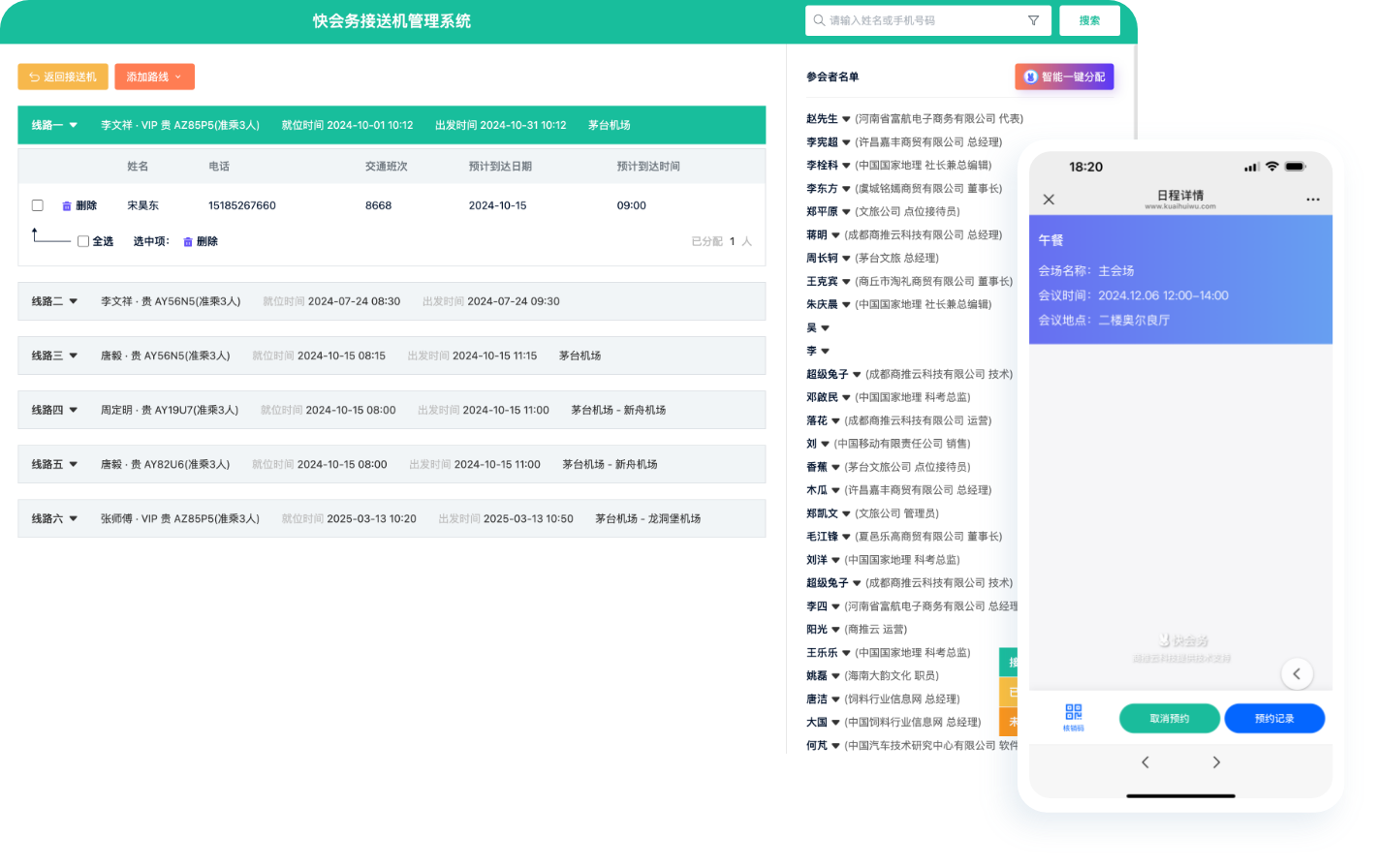
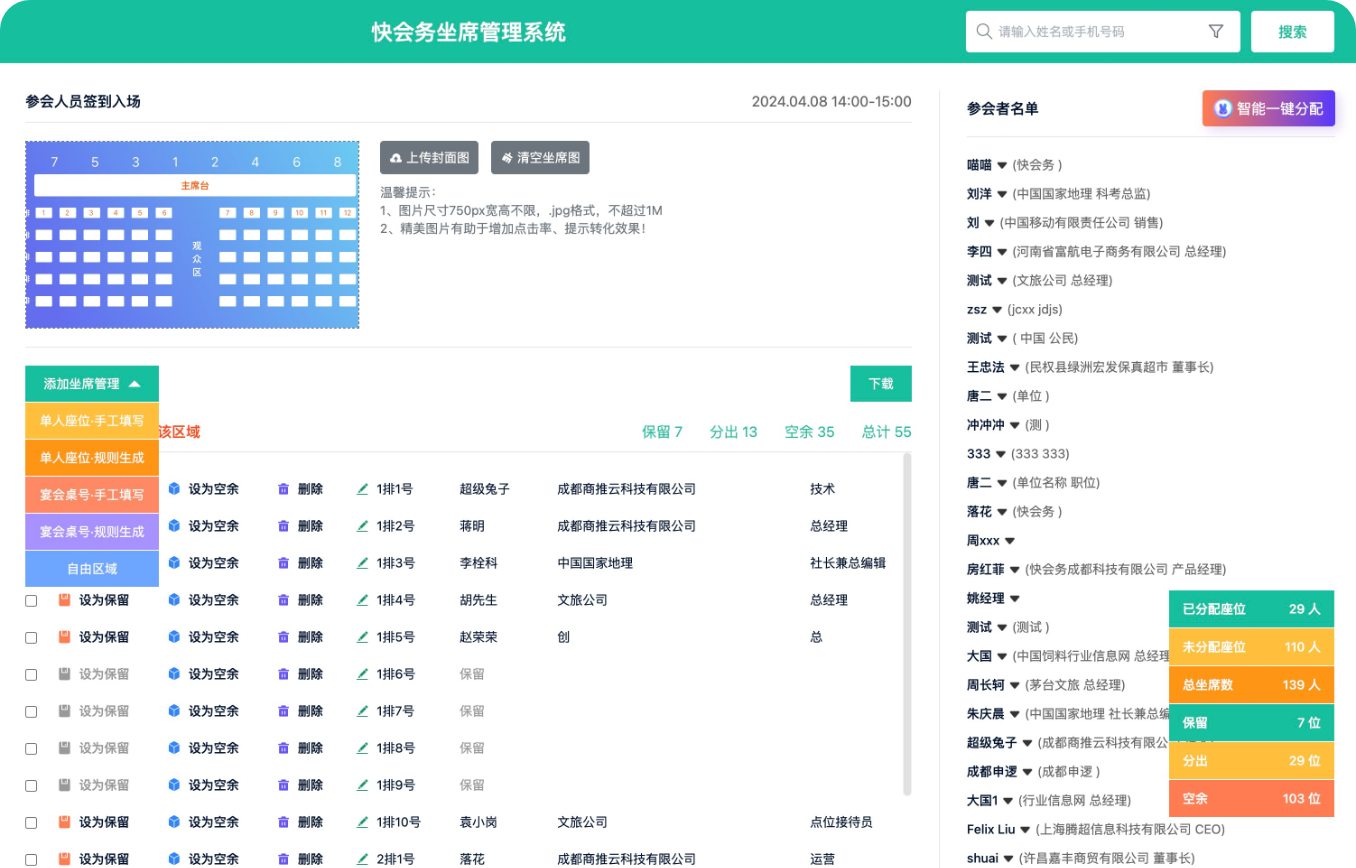
中小活动管理系统
报名缴费、电子签到、分销管理

邀请函系统
H5邀请函,动画、报名字段自定义

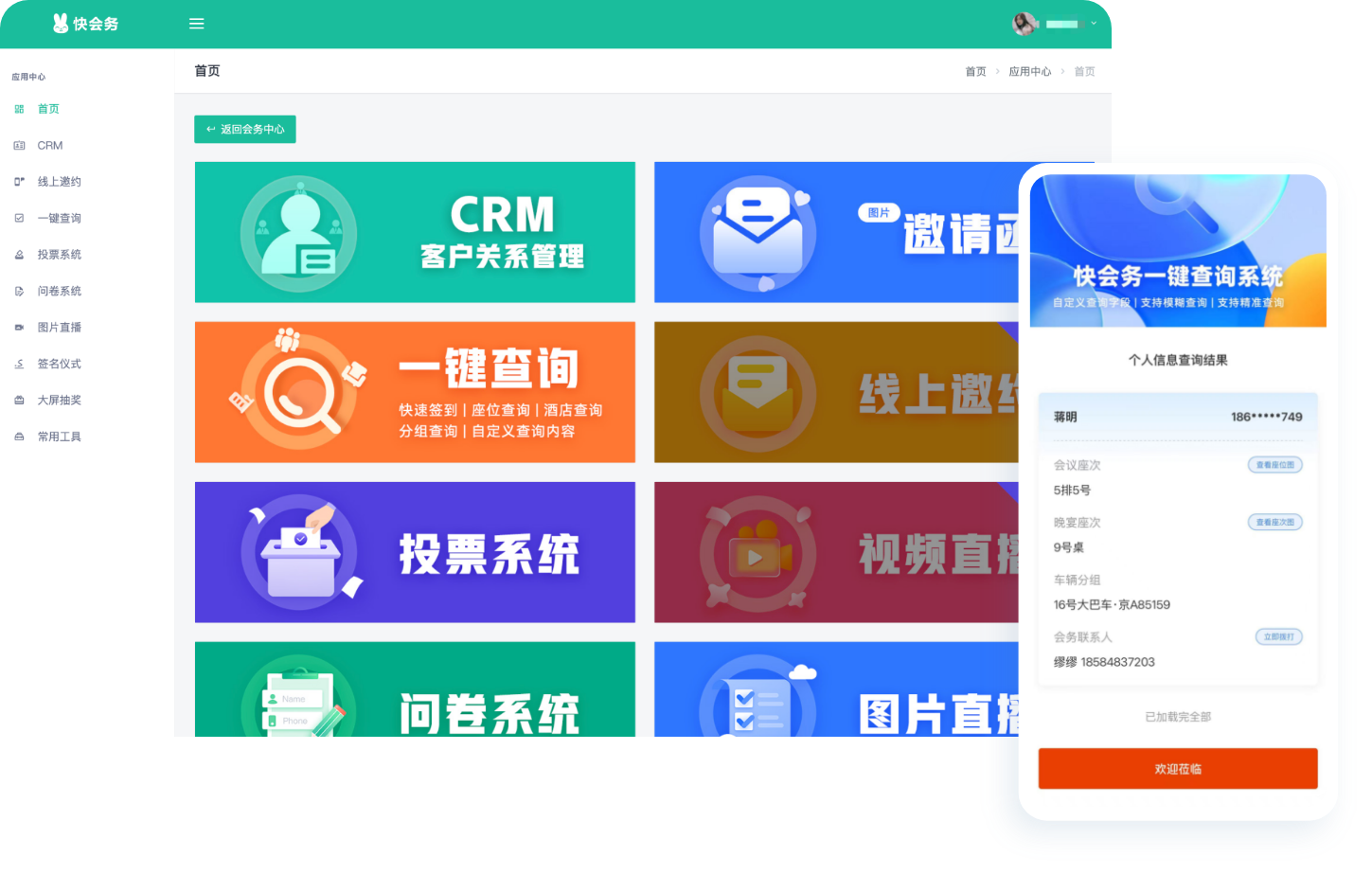
一键查询系统
查询字段自定义、数据一键导入

线上展会解决方案
微展通线上展会平台,招商招观利器

展会主场管理系统
在线报馆审图,数字化更简便更高效
解决方案
国际大会解决方案
政府会议解决方案
展览会解决方案
学术会解决方案
协会社团解决方案
企业级活动管理解决方案
分销商大会解决方案
线上活动解决方案
线上展会解决方案
主场管理解决方案
报馆审图解决方案
展商管理解决方案
展馆管理解决方案
邀请函解决方案
一键查询解决方案
服务支持
开通服务
后台使用培训讲解
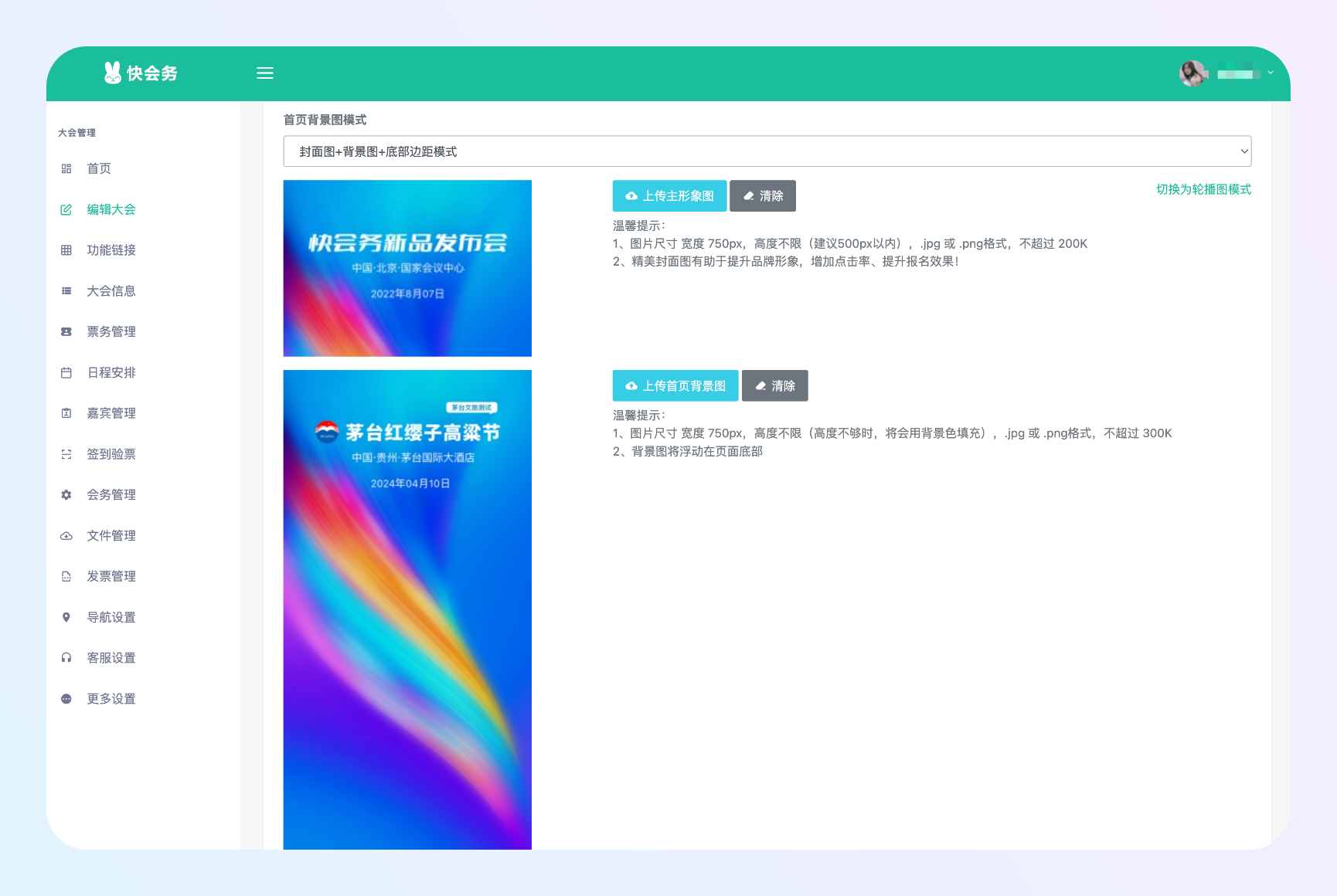
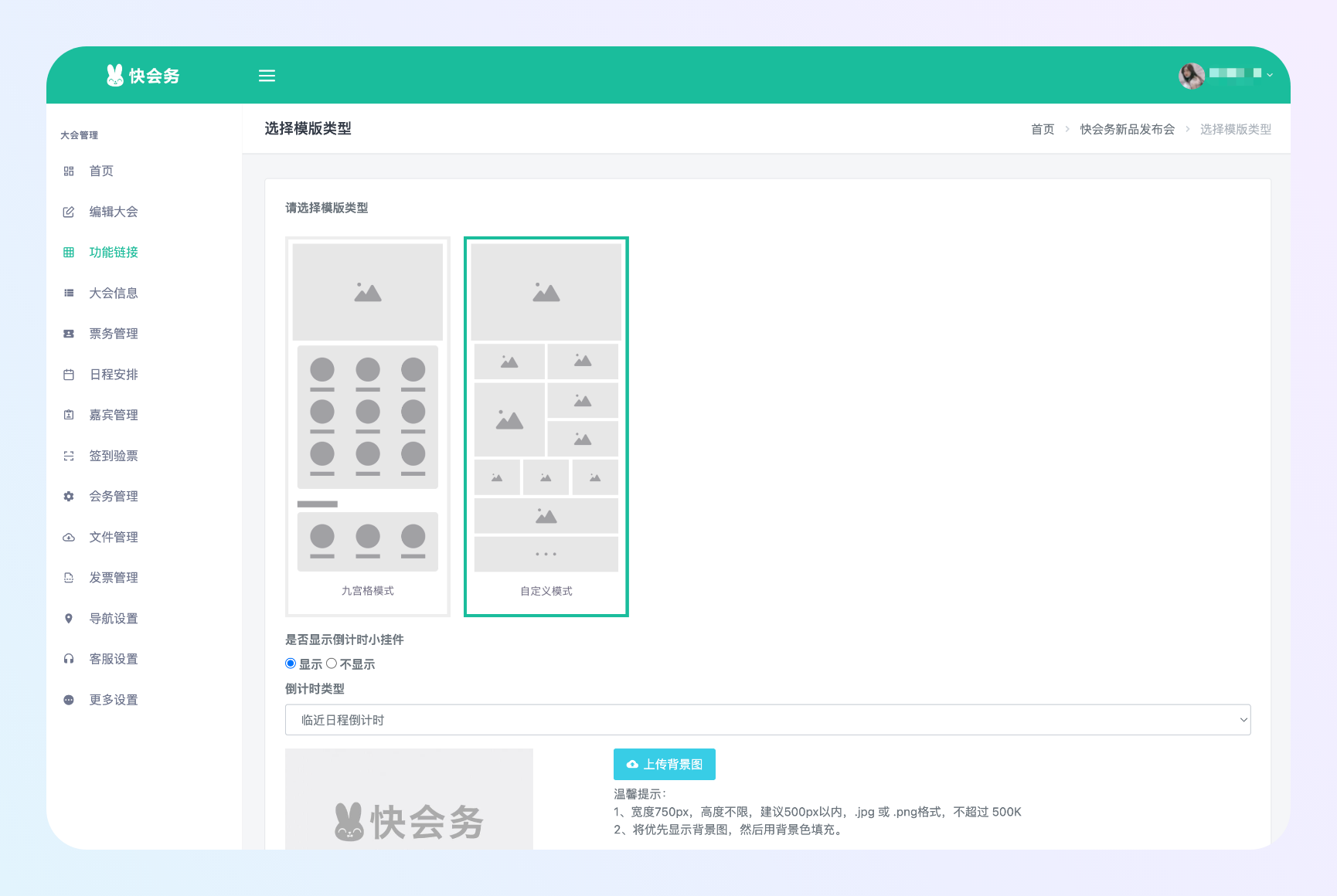
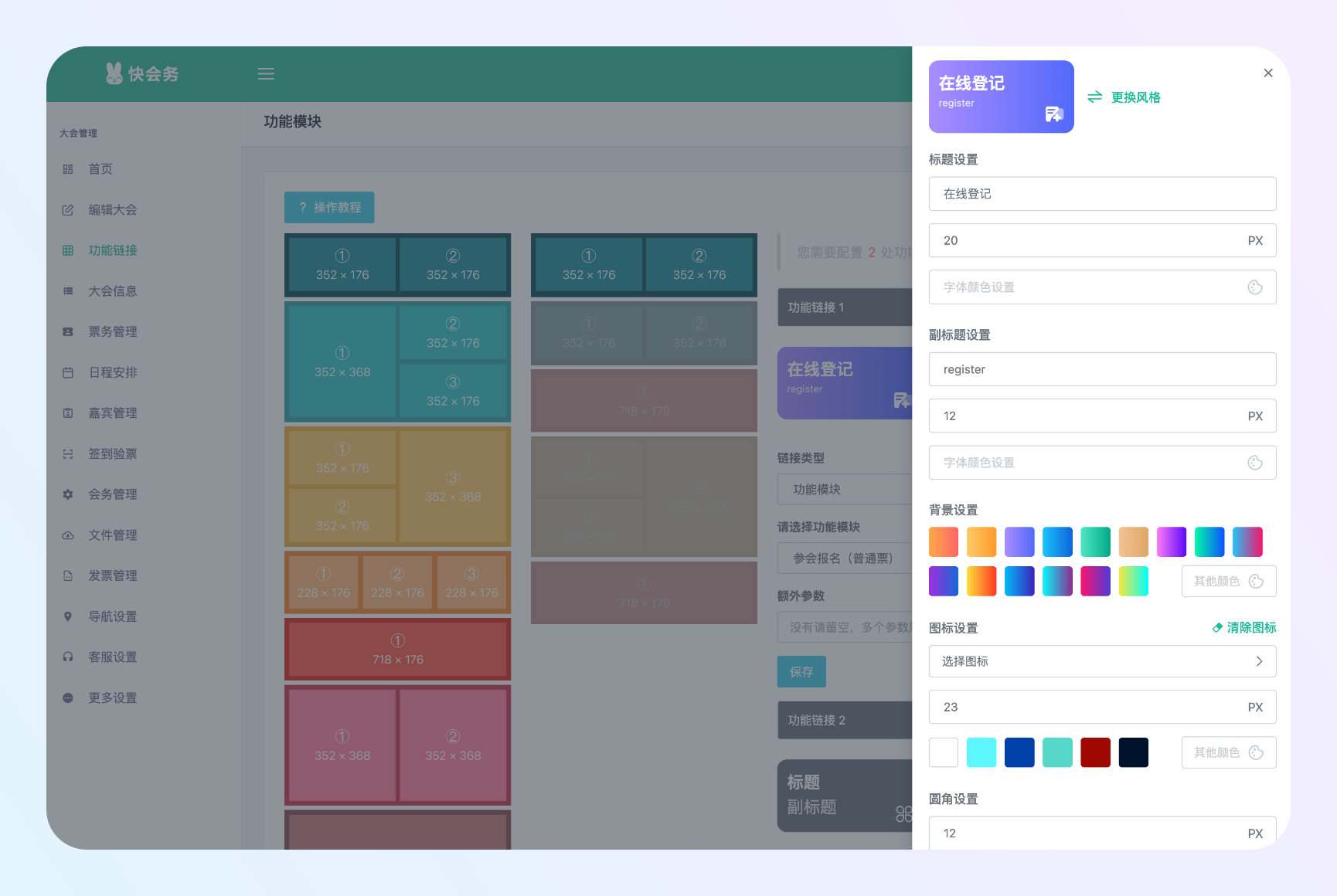
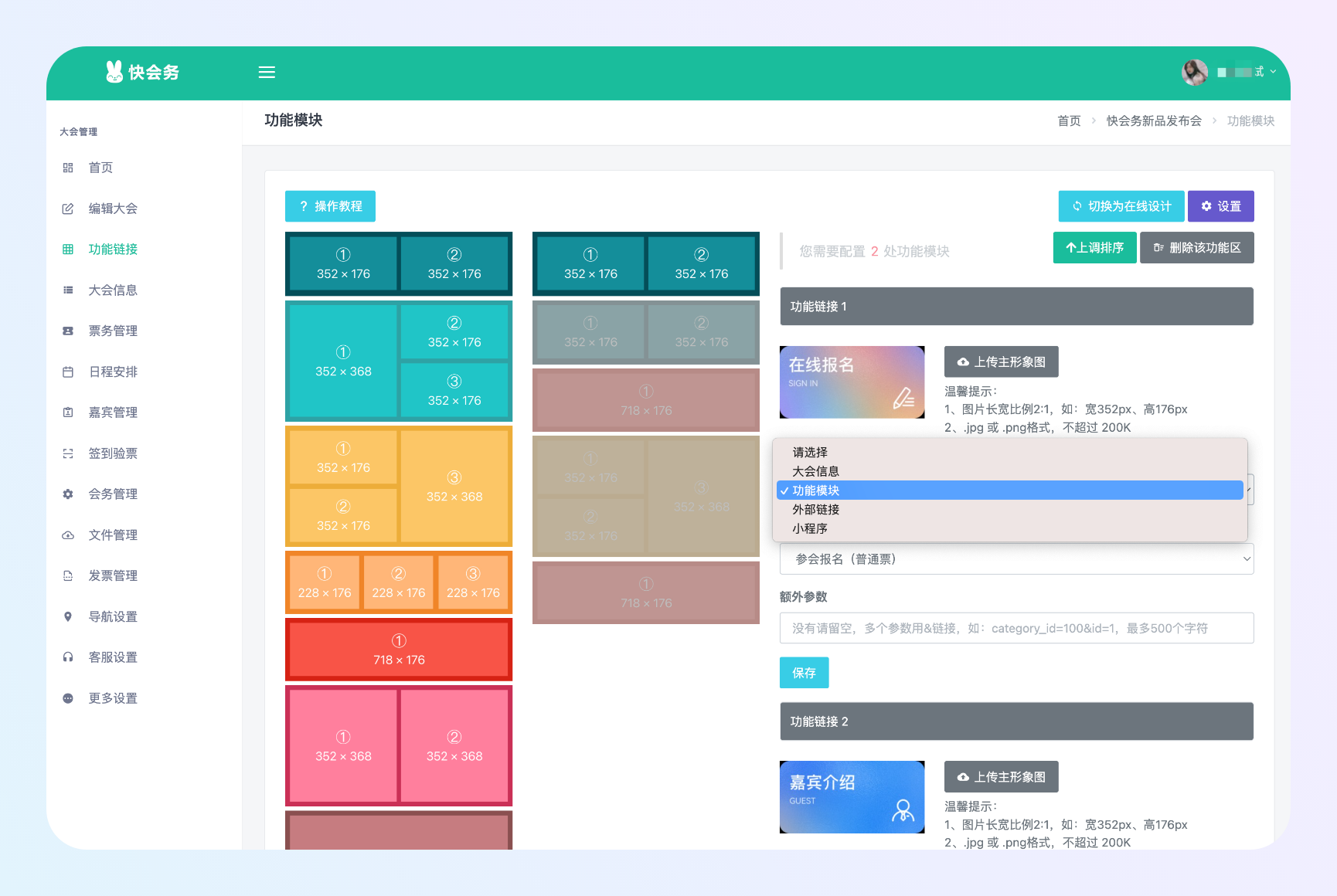
创建、配置大会
技术支持
大会帮助中心
活动帮助中心